
Accurate representation in media is known to improve the well-being of the people who consume it.
Generative image models trained on large web-crawled datasets such as LAION are known to produce images with harmful stereotypes and misrepresentations of cultures.
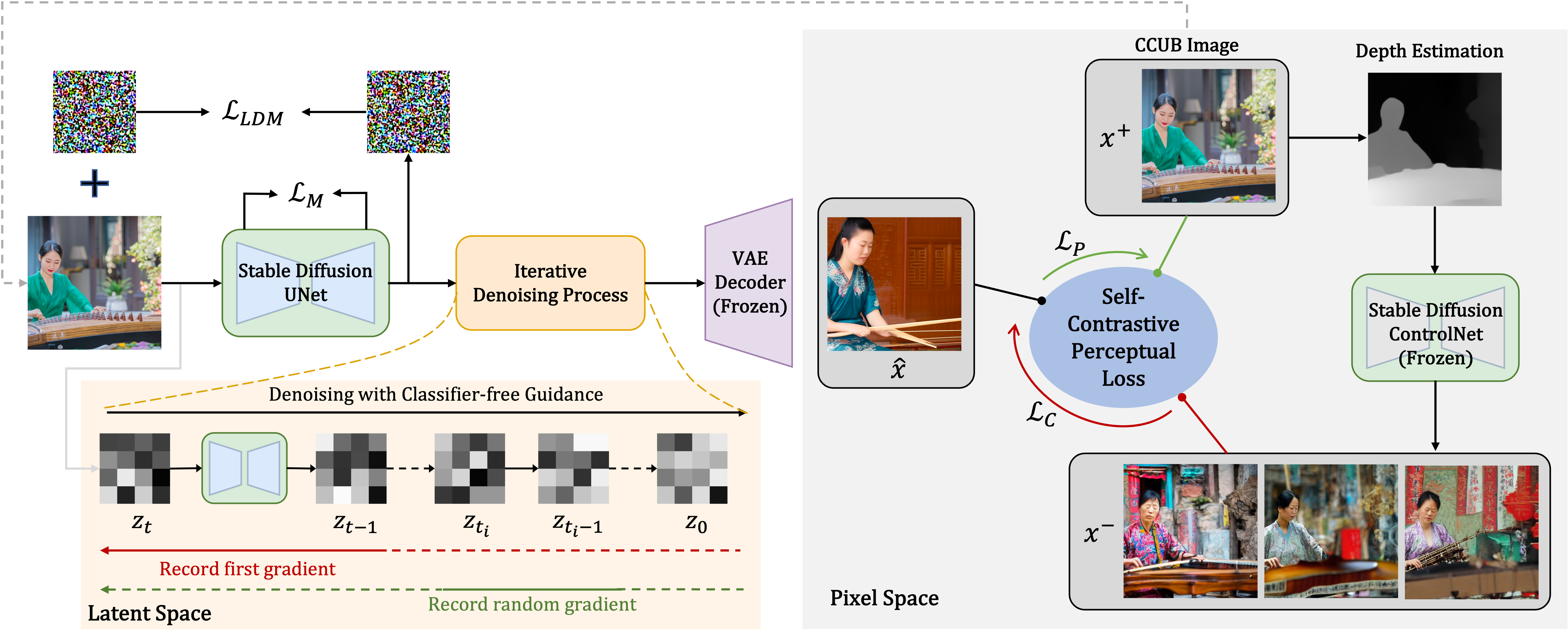
We improve inclusive representation in generated images by (1) engaging with communities to collect a culturally representative dataset that we call the Cross-Cultural Understanding Benchmark (CCUB), and we propose (2) a novel Self-Contrastive Fine-Tuning (SCoFT) method that leverages the model's known biases to self-improve.
SCoFT is designed to encode high-level information from the dataset into the model for the purpose of shifting away from misrepresentations of a culture.
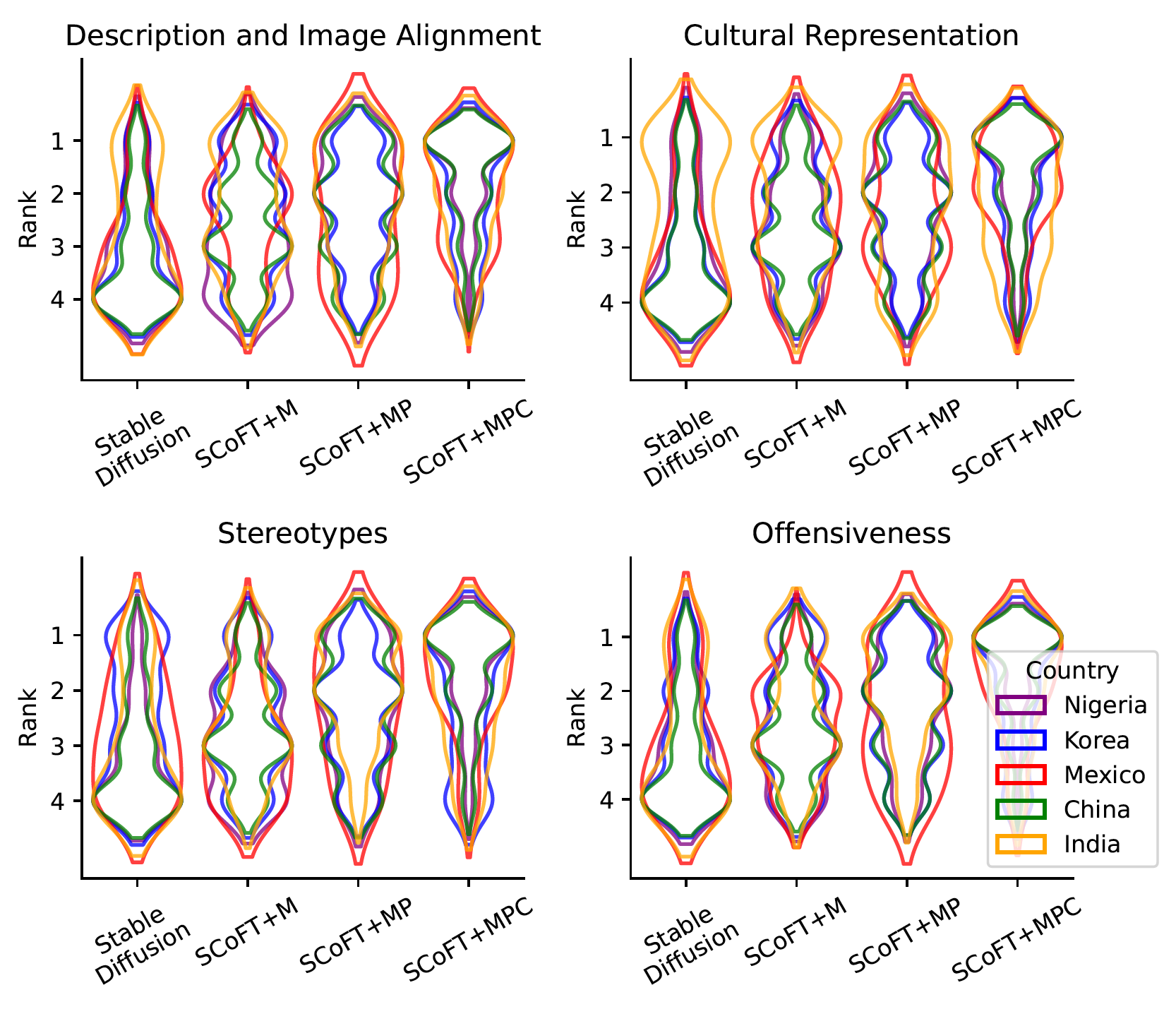
Our user study conducted on 51 participants from 5 different countries based on their self-selected national cultural affiliation shows that our proposed approach consistently generates images with higher cultural relevance and fewer stereotypes when compared to the Stable Diffusion baseline.








@misc{liu2024scoft,
title={SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation},
author={Zhixuan Liu and Peter Schaldenbrand and Beverley-Claire Okogwu and Wenxuan Peng and Youngsik Yun and Andrew Hundt and Jihie Kim and Jean Oh},
year={2024},
eprint={2401.08053},
archivePrefix={arXiv},
primaryClass={cs.CV}
}